Anthropic legt mit Claude Opus 4.6 nach, bringt Kontextfenster mit 1 Million Token





Sie sitzen gerade am Drücker, und das wissen sie – und nutzen das Zeitfenster, um möglichst viele Meter gegen die Konkurrenz zu machen: Anthropic, das gerade mit Claude Cowork SaaS-Aktien auf Talfahrt schickte, hat am Donnerstag Abend zwar nicht Claude 5 veröffentlicht, aber seinen kleinen Bruder – nämlich Claude Opus 4.6.
Das neue Modell verbessert die Programmierfähigkeiten seines Vorgängers Opus 4.5 erheblich: Es plant sorgfältiger, bewältigt agentenbasierte Aufgaben über längere Zeiträume, arbeitet zuverlässiger in größeren Codebasen und erkennt eigene Fehler durch verbesserte Debugging-Funktionen, heißt es seitens des Unternehmens.
Erstmals verfügt ein Modell der Opus-Klasse über ein Kontextfenster von einer Million Token, das sich derzeit in der Betaphase befindet. Es gibt nicht viele andere KI-Modelle am Markt, die derart große Daten verarbeiten können – unter anderem Gemini von Google.
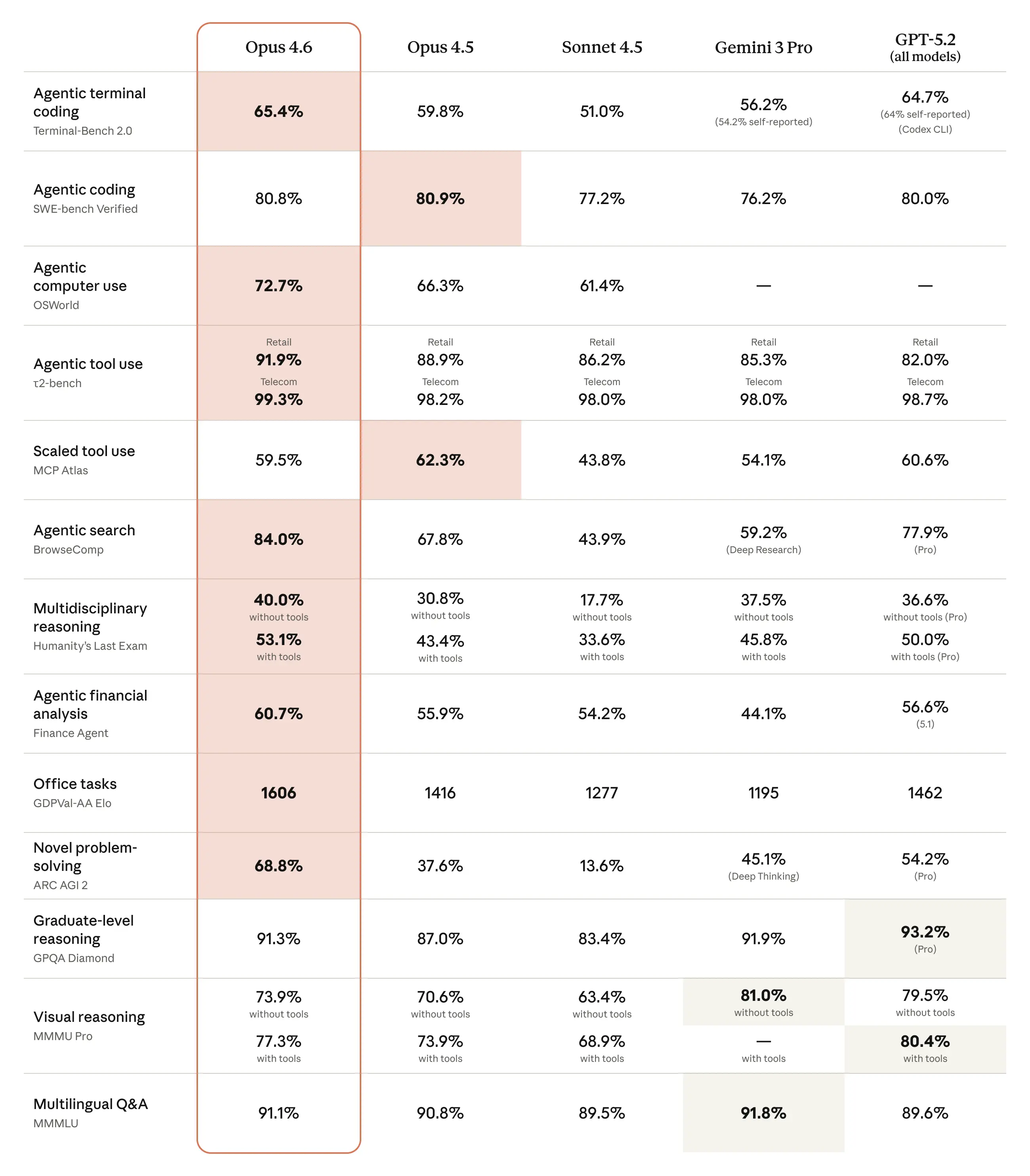
In von Anthropic veröffentlichten Leistungstests zeigt Opus 4.6 deutliche Fortschritte gegenüber Konkurrenzmodellen. Beim GDPval-AA-Benchmark, der die Leistung bei wirtschaftlich wertvollen Wissensarbeitsaufgaben in Bereichen wie Finanzen und Recht misst, übertrifft das Modell OpenAIs GPT-5.2 um etwa 144 Elo-Punkte und seinen eigenen Vorgänger um 190 Punkte. Bei Terminal-Bench 2.0, einer Evaluation für agentenbasiertes Programmieren, erreicht Opus 4.6 die höchste Punktzahl aller getesteten Modelle. Auch bei Humanity’s Last Exam, einem komplexen multidisziplinären Denktest, führt das Modell vor allen anderen Frontier-Modellen. Im BrowseComp-Test, der die Fähigkeit misst, schwer auffindbare Informationen online zu lokalisieren, erzielt Opus 4.6 ebenfalls Spitzenwerte.
Erweiterte Fähigkeiten für Entwicklung und Wissensarbeit
Das Modell demonstriert besonders bei der Verarbeitung langer Kontexte erhebliche Verbesserungen. Beim MRCR v2-Benchmark in der Variante mit acht versteckten Informationen in einer Million Token erreicht Opus 4.6 eine Trefferquote von 76 Prozent, während Sonnet 4.5 lediglich 18,5 Prozent erzielt. Diese Leistungssteigerung bedeutet einen qualitativen Wandel in der Menge an Kontext, die ein Modell tatsächlich nutzen kann, ohne dass die Spitzenleistung nachlässt. Das Modell findet Informationen über lange Kontexte hinweg präziser, verarbeitet diese Informationen mit verbesserter Denkleistung und verfügt über deutlich bessere Fähigkeiten im Expertendenken. Die erweiterten Fähigkeiten lassen sich auf verschiedene alltägliche Arbeitsaufgaben anwenden, darunter Finanzanalysen, Recherchen sowie die Nutzung und Erstellung von Dokumenten, Tabellen und Präsentationen.
Anthropic hat umfangreiche Produktaktualisierungen eingeführt, um die Leistungsfähigkeit von Opus 4.6 optimal zu nutzen. In Claude Code können Entwickler nun Agententeams zusammenstellen, die parallel an Aufgaben arbeiten und sich autonom koordinieren – besonders geeignet für Aufgaben wie Codebase-Reviews, die sich in unabhängige Teilarbeiten aufteilen lassen. Über die API stehen Entwicklern neue Funktionen zur Verfügung: Adaptives Denken ermöglicht es dem Modell, selbst zu entscheiden, wann tieferes Nachdenken hilfreich wäre, während vier Anstrengungsstufen von niedrig bis maximal präzise Kontrolle über Intelligenz, Geschwindigkeit und Kosten bieten.
Die Kontextverdichtung fasst automatisch älteren Kontext zusammen, wenn Gespräche einen konfigurierbaren Schwellenwert erreichen, sodass längere Aufgaben ohne Limitüberschreitung durchgeführt werden können. Das Modell unterstützt zudem Ausgaben von bis zu 128.000 Token und ermöglicht damit die Fertigstellung größerer Aufgaben ohne Aufteilung in mehrere Anfragen.
Sicherheit und Ausrichtung im Fokus
Die Intelligenzgewinne gehen nicht zulasten der Sicherheit, heißt es weiter. Bei automatisierten Verhaltensaudits zeigte Opus 4.6 niedrige Raten fehlausgerichteten Verhaltens wie Täuschung, Schmeichelei, Förderung von Nutzertäuschungen und Kooperation bei Missbrauch. Insgesamt ist das Modell mindestens ebenso gut ausgerichtet wie sein Vorgänger Opus 4.5, der bisher das am besten ausgerichtete Frontier-Modell war. Opus 4.6 weist zudem die niedrigste Rate übermäßiger Ablehnungen aller jüngeren Claude-Modelle auf, bei denen das Modell harmlose Anfragen fälschlicherweise ablehnt. Anthropic hat für Opus 4.6 die umfassendste Reihe von Sicherheitsevaluationen durchgeführt, darunter neue Tests für Nutzerwohlbefinden, komplexere Prüfungen der Fähigkeit des Modells, potenziell gefährliche Anfragen abzulehnen, und aktualisierte Evaluationen der Fähigkeit, heimlich schädliche Aktionen auszuführen. Da das Modell verbesserte Cybersicherheitsfähigkeiten aufweist, hat das Unternehmen sechs neue Cybersicherheits-Sonden entwickelt, um verschiedene Formen potenziellen Missbrauchs zu erkennen und zu verfolgen.
Claude Opus 4.6 ist ab sofort auf claude.ai, über die API und auf allen großen Cloud-Plattformen verfügbar. Entwickler können das Modell über die Kennung claude-opus-4-6 nutzen. Die Preisgestaltung bleibt unverändert bei 5 Dollar für eine Million Eingabe-Token und 25 Dollar für eine Million Ausgabe-Token. Für Eingaben, die 200.000 Token überschreiten, gilt eine Premium-Preisgestaltung von 10 Dollar für Eingabe-Token und 37,50 Dollar für Ausgabe-Token. Für Arbeitslasten, die in den Vereinigten Staaten ausgeführt werden müssen, steht eine auf die USA beschränkte Inferenz zum 1,1-fachen Token-Preis zur Verfügung. Das Unternehmen hat außerdem wesentliche Verbesserungen an Claude in Excel vorgenommen und Claude in PowerPoint als Forschungsvorschau veröffentlicht, wodurch das Modell für alltägliche Arbeitsaufgaben deutlich leistungsfähiger wird.
Natürlich will Anthropic in vielen Punkten besser sein als Google und OpenAI. Abzuwarten bleibt, ob Opus 4.6 auch bei Arena.ai punkten wird können: