Anthropic Releases Claude Opus 4.6 with Million-Token Context Window and Enhanced Coding Capabilities





They are currently holding the advantage, and they know it – and are using this window of opportunity to gain as many meters as possible against the competition: Anthropic, which just sent SaaS stocks on a downward spiral with Claude Cowork, did not release Claude 5 on Thursday evening, but its little brother – namely Claude Opus 4.6.
The new model significantly improves the programming capabilities of its predecessor Opus 4.5: It plans more carefully, handles agent-based tasks over longer periods, works more reliably in larger codebases, and recognizes its own errors through improved debugging functions, according to the company.
For the first time, a model in the Opus class features a context window of one million tokens, which is currently in beta. There are not many other AI models on the market that can process such large amounts of data – including Google’s Gemini, among others.
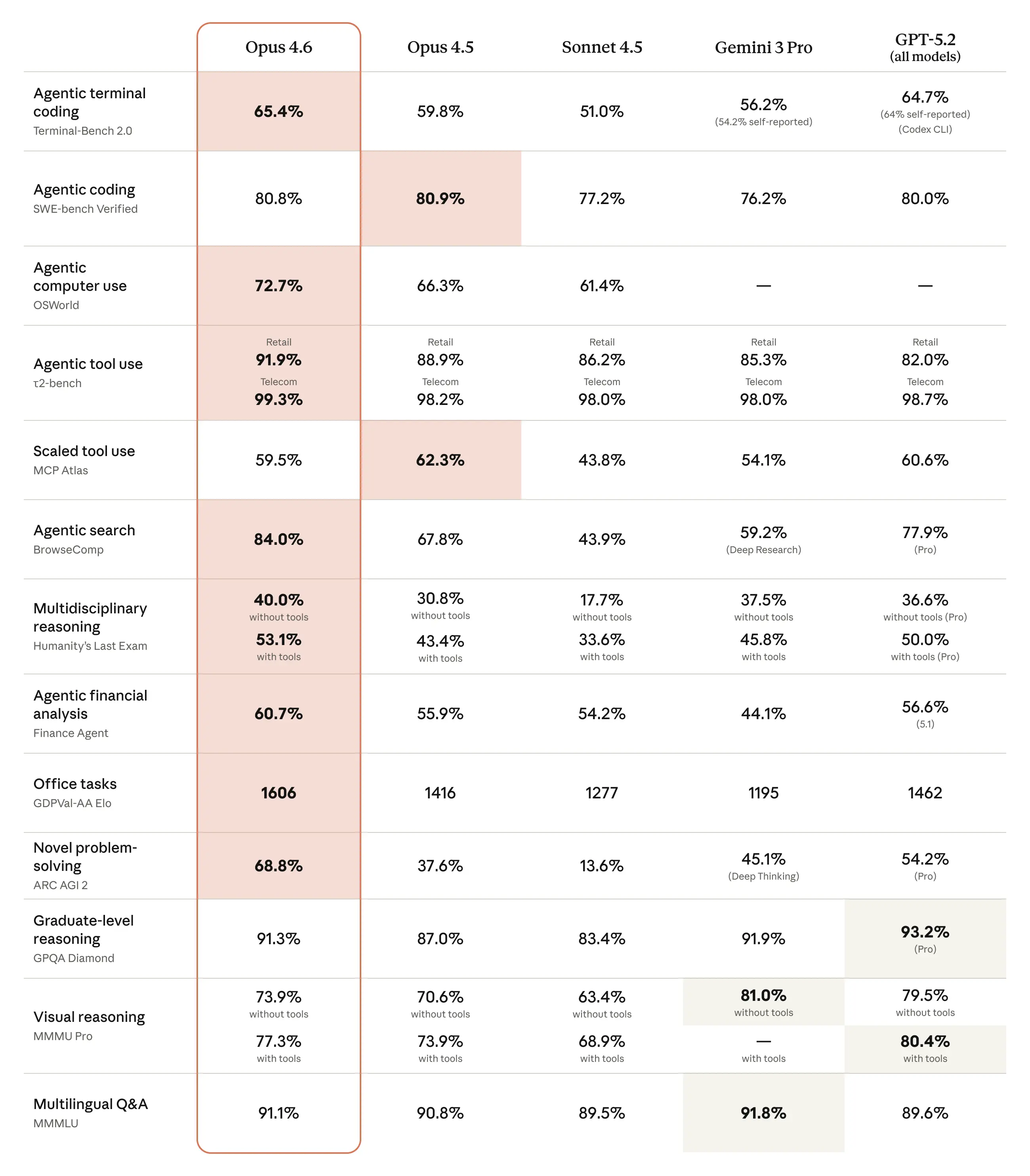
In performance tests published by Anthropic, Opus 4.6 shows significant progress compared to competing models. On the GDPval-AA benchmark, which measures performance on economically valuable knowledge work tasks in areas such as finance and law, the model outperforms OpenAI’s GPT-5.2 by approximately 144 Elo points and its own predecessor by 190 points. On Terminal-Bench 2.0, an evaluation for agent-based programming, Opus 4.6 achieves the highest score of all tested models. It also leads all other frontier models on Humanity’s Last Exam, a complex multidisciplinary reasoning test. In the BrowseComp test, which measures the ability to locate hard-to-find information online, Opus 4.6 also achieves top scores.
Enhanced capabilities for development and knowledge work
The model demonstrates significant improvements particularly in processing long contexts. On the MRCR v2 benchmark in the variant with eight hidden pieces of information in one million tokens, Opus 4.6 achieves a hit rate of 76 percent, while Sonnet 4.5 achieves only 18.5 percent. This performance increase represents a qualitative shift in the amount of context a model can actually use without peak performance declining. The model finds information across long contexts more precisely, processes this information with improved reasoning power, and has significantly better expert thinking capabilities. The enhanced capabilities can be applied to various everyday work tasks, including financial analysis, research, and the use and creation of documents, spreadsheets, and presentations.
Anthropic has introduced comprehensive product updates to optimally leverage the capabilities of Opus 4.6. In Claude Code, developers can now assemble agent teams that work in parallel on tasks and coordinate autonomously – particularly suitable for tasks like codebase reviews that can be split into independent subtasks. Via the API, developers have access to new features: Adaptive thinking enables the model to decide for itself when deeper reasoning would be helpful, while four effort levels from low to maximum provide precise control over intelligence, speed, and cost.
Context compression automatically summarizes older context when conversations reach a configurable threshold, allowing longer tasks to be performed without exceeding limits. The model also supports outputs of up to 128,000 tokens, enabling the completion of larger tasks without splitting into multiple requests.
Security and alignment in focus
The intelligence gains do not come at the expense of security, the company states. In automated behavior audits, Opus 4.6 showed low rates of misaligned behavior such as deception, flattery, promotion of user deception, and cooperation in abuse. Overall, the model is at least as well aligned as its predecessor Opus 4.5, which was previously the best-aligned frontier model. Opus 4.6 also exhibits the lowest rate of excessive refusals among recent Claude models, where the model incorrectly refuses harmless requests. Anthropic has conducted the most comprehensive set of security evaluations for Opus 4.6, including new tests for user well-being, more complex checks of the model’s ability to refuse potentially dangerous requests, and updated evaluations of the ability to covertly perform harmful actions. Since the model has improved cybersecurity capabilities, the company has developed six new cybersecurity probes to detect and track various forms of potential misuse.
Claude Opus 4.6 is now available on claude.ai, via the API, and on all major cloud platforms. Developers can use the model via the identifier claude-opus-4-6. Pricing remains unchanged at $5 per million input tokens and $25 per million output tokens. For inputs exceeding 200,000 tokens, premium pricing of $10 for input tokens and $37.50 for output tokens applies. For workloads that must be executed in the United States, US-restricted inference is available at 1.1 times the token price. The company has also made substantial improvements to Claude in Excel and released Claude in PowerPoint as a research preview, making the model significantly more powerful for everyday work tasks.
Of course, Anthropic wants to be better than Google and OpenAI in many respects. It remains to be seen whether Opus 4.6 will be able to score at Arena.ai: