Meta Llama 4 stürzt nach Trickserei hart in wichtigem Ranking ab




Es ist ein PR-Desaster der besonderen Art: Nachdem bekannt wurde, dass Meta bei seinem neuesten AI-Modell „Llama 4 Maverick“ getrickst hat, ist dieses in einem wichtigen Branchen-Ranking abgestürzt. Das KI-Modell, dass es eigentlich mit den Top-Modellen von Google, OpenAI und Co mithalten sollte, rangiert bei der wichtigen Chatbot Arena nun nur mehr auf Rang 32 – sogar hinter KI-Modellen, die längst überholt sind.
Was ist passiert? Wie berichtet hat Meta vor eineinhalb Wochen die ersten AI-Modelle seiner neuen Llama 4-Serie veröffentlicht, und zwar das kleine „Scout“ und das mittelgroße „Maverick“ – das Top-Model „Behemoth“ wird noch zurückgehalten, es ist wohl noch nicht fertig. In Benchmarks, die Meta selbst veröffentlicht hat, soll Llama 4 Maverick es mit GPT-4.5 von OpenAI und Grok-3 von xAI aufnehmen können.
Doch wichtiger als hauseigene Vergleichswerte ist das Ranking der Chatbot Arena, wo Nutzer:innen selbst die Leistung von KI-Modellen in unterschiedlichen Kategorien und Aspekten bewerten. Dort hat Meta allerdings wie berichtet eine speziell für diese Benchmarking-Plattform optimierte Version von Maverick, nämlich „Llama-4-Maverick-03-26-Experimental“ zur Verfügung gestellt. Dieses wurde auch schnell sehr gut bewertet, weswegen diese Version kurze Zeit sogar auf Platz 2 des Rankings landete.
Llama 4 Maverick hat keine Chance gegen Top-Modelle von Google, OpenAI und Co
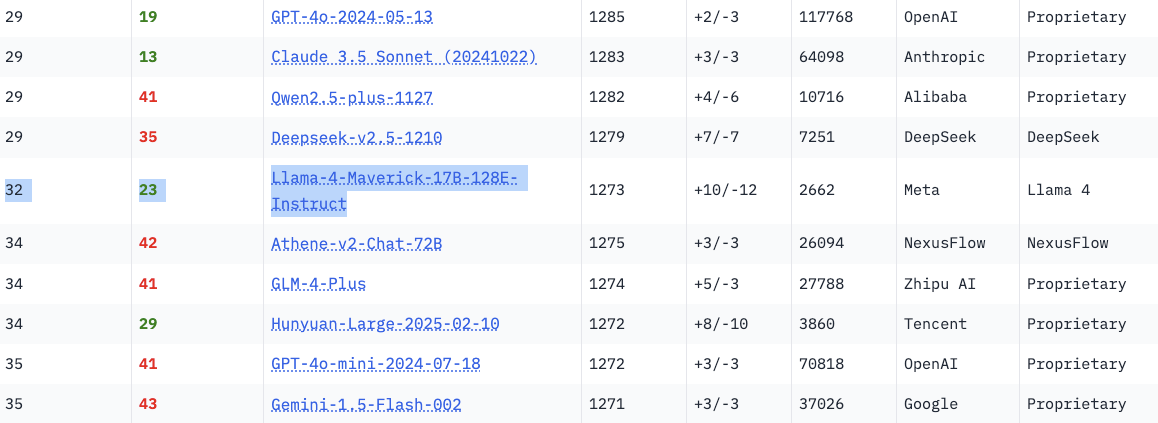
Jedoch: Diese Experimental-Version ist nicht das, was Programmierer und Unternehmen bekommen, wenn sie Llama 4 Maverick von Meta beziehen. Stattdessen bekommen sie eigentlich das Original, nämlich „Llama-4-Maverick-17B-128E-Instruct„. Nach der Trickserei von Meta, die aufflog, haben, die Macher der Chatbot Arena die getrickste Experimental-Version entfernt und stattdessen die Instruct-Version zum Test freigegeben.
Und siehe da: Das „echte“ Maverick-Modell ist eigentlich ziemlich schlecht und landet im Ranking nur auf Platz 32. Wohlgemerkt hinter Versionen von GPT-40 (OpenAI), DeepSeek oder Claude (Anthropic), die längst durch bessere KI-Modelle überholt wurden. Damit stellt sich die große Frage: Ist Llama 4 überhaupt konkurrenzfähig? Oder wollte man vertuschen, dass Meta trotz Milliardeninvestitionen nicht mehr mit Google, OpenAI, Anthropic oder xAi mithalten kann?