Leak: Model Card gewährt erste tiefere Einblicke in Gemini 3 Pro





Die entsprechenden Gerüchte gibt es seit Wochen, die Bestätigung für den baldigen Release seit wenigen Tagen – und nun folgt noch dieser Leak: Ja genau, die Veröffentlichung von Googles neuestem KI-Modell Gemini 3 Pro steht unmittelbar bevor und soll bereits nächste Woche erfolgen. Viele fragen sich da natürlich: Wie stark wird das LLM, und wie schlägt es sich gegen die Konkurrenz?
Offenbar ist Google zur Beantwortung dieser Frage – unabsichtlich oder nicht – die so genannte Model Card, also quasi der Beipackzettel für das LLM, auf einer Google-betriebenen Webseite entfleucht. Wie so oft gelang es nicht ganz, das Dokument wieder einzufangen, auf Wayback Machine ist es weiterhin zu finden. Darin zu lesen ist wenig Überraschendes: So soll Gemini 3 Pro nicht nur besser sein als sein Vorgänger Gemini 2.5 Pro, sondern auch als die beiden Mitbewerber.
Im Vergleich zu Claude und ChatGPT
Im Vorfeld hat Google-CEO Sundar Pichai aber bereits Expactation Management betrieben und zu Investoren gesagt: „Manchmal nehmen wir uns bewusst die Zeit, ein deutlich besseres Modell zu veröffentlichen.“ Das deutet schon darauf hin, dass der wirklich große nächste Wurf erst mit Gemini 4 oder 5 zu erwarten ist.
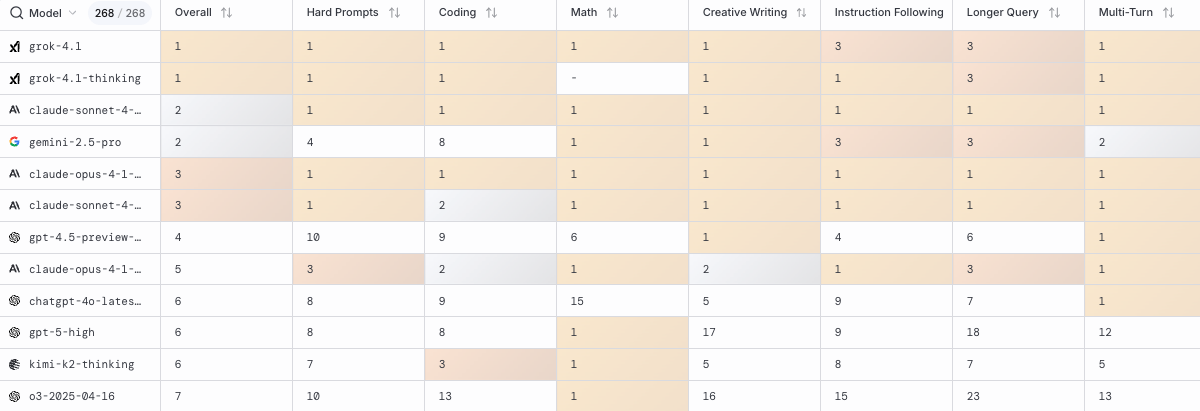
Nichtsdestotrotz soll Gemini 3 Pro – natürlich – besser sein als das, was die größten Konkurrenten derzeit so auf Lager haben. Gemeint sind dabei GPT-5.1 von OpenAI sowie Claude Sonnet 4.5 von Anthropic. Das geht aus den Benchmarks hervor, die in der Model Card von Gemini 3 Po enthalten sind. Diese stellen, wie in der Branche üblich, dar, welche Punktezahl das KI-Modell bei unterschiedlichen Testläufen (z.B. Humanity’s Last Exam“) erreichte. Hier zeigt sich, dass Gemini 3 Pro einfach überall besser sein soll als die derzeit stärksten LLMs von OpenAI und Anthropic:
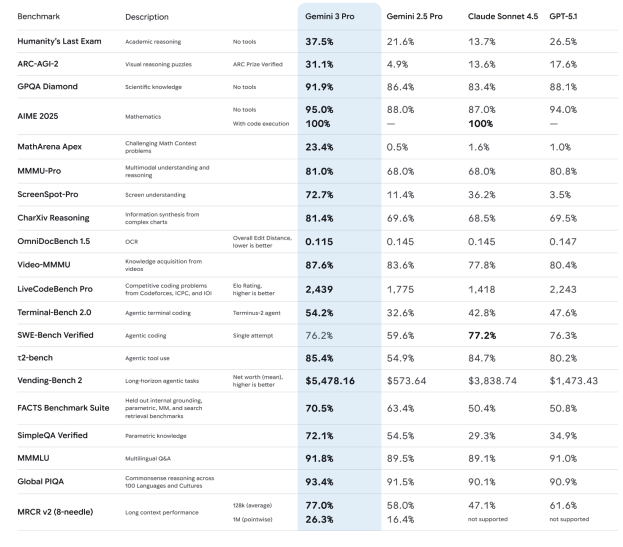
Mit Google-Chips trainiert
In der Model Card wird Gemini 3 Pro als „Googles fortschrittlichstes Modell für komplexe Aufgaben“ dargestellt. Das Modell gehöre zur nächsten Generation der Gemini-Serie und könne „umfangreiche Datensätze und herausfordernde Probleme aus verschiedenen Informationsquellen verarbeiten, einschließlich Text, Audio, Bilder, Video und gesamte Code-Repositories“. Mit einem Kontext-Fenster von bis zu 1 Million Token und einer Ausgabe von 64.000 Token positioniert sich Gemini 3 Pro als Googles leistungsfähigstes KI-System für Reasoning-Aufgaben.
Die technische Basis bildet eine Mixture-of-Experts-Architektur (MoE), bei der pro Input-Token nur eine Teilmenge der Modellparameter aktiviert wird – quasi so, wie nur bestimmte Hirnregionen beim Menschen für bestimmte Dinge zuständig sind.
Das „Transformer-basierte Modell mit nativer multimodaler Unterstützung für Text, Vision und Audio-Eingaben“ wurde auf Googles hauseigenen Tensor Processing Units (TPUs) trainiert, wobei JAX und ML Pathways als Software-Framework dienten. Das Pre-Training umfasste „eine groß angelegte, diverse Datensammlung aus einem breiten Spektrum von Domänen und Modalitäten“, darunter öffentlich verfügbare Web-Dokumente, Code in verschiedenen Programmiersprachen, Bilder, Audio und Video. Das Post-Training nutzte Reinforcement Learning mit „mehrstufigen Reasoning-, Problemlösungs- und Theorembeweis-Daten“.
Performance und Evaluierung
Gemini 3 Pro hat nach Google-Angaben „Gemini 2.5 Pro über eine Reihe von Benchmarks hinweg deutlich übertroffen“, die erweiterte Reasoning- und multimodale Fähigkeiten erfordern. Die internen Safety-Evaluierungen zeigen dem Dokument zufolge ein differenziertes Bild: Bei Text-zu-Text-Safety verbesserte sich das Modell um 10,4 Prozent (weniger Verstöße), beim Ton der Modell-Ablehnungen um 7,9 Prozent und bei ungerechtfertigten Ablehnungen um 3,7 Prozent. Die multilinguale Safety blieb mit plus 0,2 Prozent nahezu stabil, während Image-zu-Text-Safety um 3,1 Prozent zulegte.
Das Red Teaming durch spezialisierte Teams außerhalb der Modellentwicklung ergab, dass Gemini 3 Pro „die erforderlichen Launch-Schwellenwerte für Kindersicherheit erfüllt hat“. Im Vergleich zu Gemini 2.5 Pro zeigte sich „ähnliche oder verbesserte Safety-Performance“. Die Frontier Safety Framework-Evaluation kam zum Ergebnis, dass das Modell „keine kritischen Fähigkeitslevel erreicht hat“ – weder bei CBRN, Cybersecurity, schädlicher Manipulation, Machine-Learning-R&D noch bei Misalignment.
Einsatzgebiete und Grenzen
Das Modell eignet sich laut Google besonders für „Anwendungen, die Agentic Performance, fortgeschrittenes Coding, Long Context und/oder multimodales Verständnis sowie algorithmische Entwicklung erfordern“. Zu den bekannten Limitierungen zählen „allgemeine Einschränkungen von Foundation Models, wie Halluzinationen“ sowie „gelegentliche Langsamkeit oder Timeout-Probleme“. Der Knowledge-Cutoff liegt bei Januar 2025. Als Hauptrisiken nennt Google die „Jailbreak-Anfälligkeit (verbessert im Vergleich zu Gemini 2.5 Pro, aber weiterhin ein offenes Forschungsproblem)“ und „mögliche Degradierung in Multi-Turn-Konversationen“.
Die Distribution soll über sechs Kanäle erfolgen: Gemini App, Google Cloud/Vertex AI, Google AI Studio, Gemini API, Google AI Mode und Google Antigravity. Googles Generative AI Prohibited Use Policy schließt Einsätze aus, die „gefährliche oder illegale Aktivitäten ausführen, die Sicherheit anderer oder Googles Services kompromittieren, sexuell explizite, gewalttätige, hasserfüllte oder schädliche Aktivitäten betreiben oder Desinformation, Falschdarstellung oder irreführende Aktivitäten ausüben“.
Nun bleibt letztendlich abzuwarten, wie sich das kommende KI-Modell in der Praxis schlagen wird, und wie es in unabhängigen Test etwa bei LMArena gegen konkurrierende LLMs abschneidet. Google hat zuletzt seine Spitzenposition mit Gemini 2.5 Pro an Grok 4.1 von xAI sowie an Claude Sonnet 4.5 von Anthropic abgeben müssen – Zeit also für Google, die Krone zurückzuerobern.