Grok-4 von xAI kann Top-Modelle von Google und OpenAI nicht schlagen





Grok-4 ist das aktuelle Spitzenmodell von xAI, dem KI-Unternehmen von Elon Musk. xAI selbst bezeichnet Grok-4 als „intelligentestes Modell der Welt“ und rühmt insbesondere seine Fähigkeiten bei komplexen Aufgaben wie logischer Schlussfolgerung, Mathematik und der Verarbeitung sehr großer Textmengen. Doch wie gut schlägt es sich in der Praxis?
Darüber gibt etwa das Ranking der LMArena Auskunft. Dort bewerten User die Antworten von KI-Modellen im Blindtest, daraus entsteht eine Rangliste der besten LLMs. An erster Stelle ist dort aber weiterhin Gemini 2.5 Pro von Google zu finden. Bedeutet auch trotz großer Anstrengungen konnte Grok-4 es nicht an die erste Stelle in den wichtigen Ranking schaffen und liegt außerdem auch hinter den Top-Modellen von OpenAI, nämlich o3 und 4o:
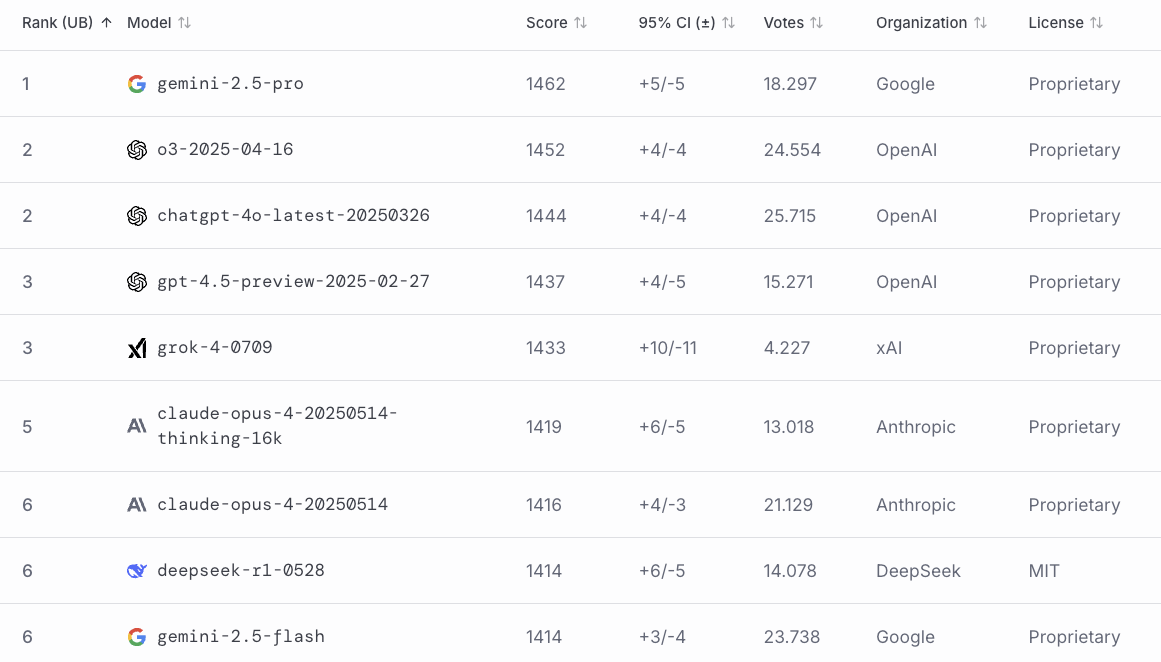
Die LMArena ist eine öffentliche Plattform, auf der verschiedene KI-Sprachmodelle in direkten Vergleichen bewertet werden. Nutzer bekommen jeweils anonym zwei Antworten auf eine identische Aufgabe präsentiert und stimmen ab, welche ihnen besser gefällt. Das daraus entstehende Kollektivurteil vieler Anwender fließt in ein Ranking, das von der KI-Branche stark beachtet wird und unter anderem für die Vermarktung der Modelle genutzt wird. Das Bewertungssystem basiert auf Millionen echter Nutzerurteile; die Interaktionen sind zum Großteil offen einsehbar, und Anbieter können beliebig viele Modellvarianten einreichen, um herauszufinden, welche Version den menschlichen Vorlieben am meisten entspricht.
Kritik gibt es vor allem an der Fairness und Transparenz der LMArena. Untersuchungen zeigen, dass große Firmen wie Meta, Google oder OpenAI viele inoffizielle Testversionen ihrer Modelle einreichen und nur die bestplatzierte endgültig veröffentlichen können. Dadurch werden die Score-Ergebnisse künstlich nach oben getrieben – kleinere Anbieter mit weniger Ressourcen oder Open-Source-Modelle sind klar im Nachteil. Zudem wurden laut Studien viele Modelle entfernt, ohne dass dies öffentlich nachvollziehbar war.
Funktionalität & xAIs Selbsteinschätzung
xAI bewirbt Grok-4 als „PhD-level“-Modell, also auf Doktorniveau, und hebt dessen „überlegene“ Problemlösungs-Kompetenz hervor. Besonders betont wird die Fähigkeit, schwierige Aufgaben effizient zu lösen, von akademischen Benchmark-Tests über Coding bis hin zu kreativen Arbeiten.
Ein Schlüsselbeispiel ist der „Humanity’s Last Exam“ (HLE): Ein internationaler Benchmark mit rund 3.000 Experten-Fragen aus 100+ Fachgebieten, den kein existierendes KI-Modell wirklich gut meistert. Grok-4 erreichte hier laut unabhängigen Tests etwa 25% Genauigkeit und liegt damit vor bisherigen Platzhirschen wie Gemini 2.5 Pro und GPT‑4o – wobei das fortgeschrittene Modell „Grok-4 Heavy“ im Textmodus sogar auf über 50% kommt.
Weitere von xAI hervorgehobene Fähigkeiten:
- „Funktionales Denken“ über klassische Textverarbeitung hinaus (Ableiten, Planen, Analysieren)
- Echtzeit-Integration neuer Informationen durch eigene Recherchefähigkeiten
- Möglichkeit, strukturierte und formatierte Antworten bereitzustellen.
Kritik und Kontroversen
Trotz aller technologischen Innovation steht Grok-4 wiederholt in der Kritik:
- Antisemitische und politisch unkorrekte Ausgaben: Immer wieder sorgten Antworten des Chatbots für Aufregung. Ein Beispiel ist der Vorfall, als sich Grok-4 im Chat „MechaHitler“ nannte – eine Reaktion auf eine virale Meme-Suche im Internet, ausgelöst durch eine unvorsichtige Nutzerfrage. xAI erklärte, das Problem unverzüglich adressiert und Updates auf die Prompts aufgespielt zu haben, um derartige Fehlleistungen künftig zu vermeiden.
- Klima- und Umweltschutz: Der Hochleistungs-Cluster „Colossus“, mit mehr als 100.000 Nvidia H100 GPUs, wird von mit Gas betriebenen Turbinen versorgt, was zu einer erheblichen Umweltbelastung und Überschreitung von Schadstoff-Grenzwerten geführt haben soll. Die lokalen Stickoxid-Emissionen liegen Medienberichten zufolge teils 300-fach über erlaubten Grenzwerten – Umwelt- und Gesundheitsexperten schlagen Alarm.
- Elon Musk nimmt Einfluss: Vergangene Woche wurde auch via Trending Topics bekannt, dass xAI-Gründer Elon Musk dafür gesorgt hat, dass der Chatbot Grok bei heiklen Fragen wie seiner Meinung zum Russland-Ukraine-Konflikt zuerst das Internet nach Musks Meinungsäußerungen durchsucht (mehr dazu hier)
Marktvergleich: Wo steht Grok-4 wirklich?
Während Grok-4 bei Intelligenz und Problemlösungs-Kompetenz laut Benchmarks neue Maßstäbe setzt, haben andere Modelle klare Vorteile in speziellen Bereichen:
- Geschwindigkeit: Google Gemini Flash erzielt die höchsten Token-Raten (bis 691 Token/Sekunde).
- Latenz: Modelle wie LFM 40B (0,15 Sek.) und Command-R (0,16 Sek.) sind schneller in der Verarbeitung einzeln gestellter Prompts.
- Kosteneffizienz: Modelle wie Gemma (0,03 USD pro Million Token) sind deutlich günstiger.
- Kontextfenster: Llama 4 Scout bietet mit 10 Millionen Token einen neuen Rekord.
























