1.200 T/s: Super-Chip-Startup Groq demonstriert blitzschnelle AI-Chatbots



Bisher lag bei AI-Tools und Large Language Models (LLMs) viel Augenmerk auf die Zahl der Parameter (meist in Milliarden, im Englisch „B“ wie „Billions“ angegeben) und die Größe der Kontextfenster. Das US-Startup Groq (nicht zu verwechseln mit dem AI-Modell „Grok“ von xAI) lenkt aktuell das Interesse aber auch die Zahl der Token, die pro Sekunde verarbeitet werden können. Denn mit seinen AI-Chips, die es Language Processing Units (LPUs) nennt, übertrifft es die Cloud-Riesen, die hauptsächlich mit Nvidia-Chips arbeiten, um Längen.
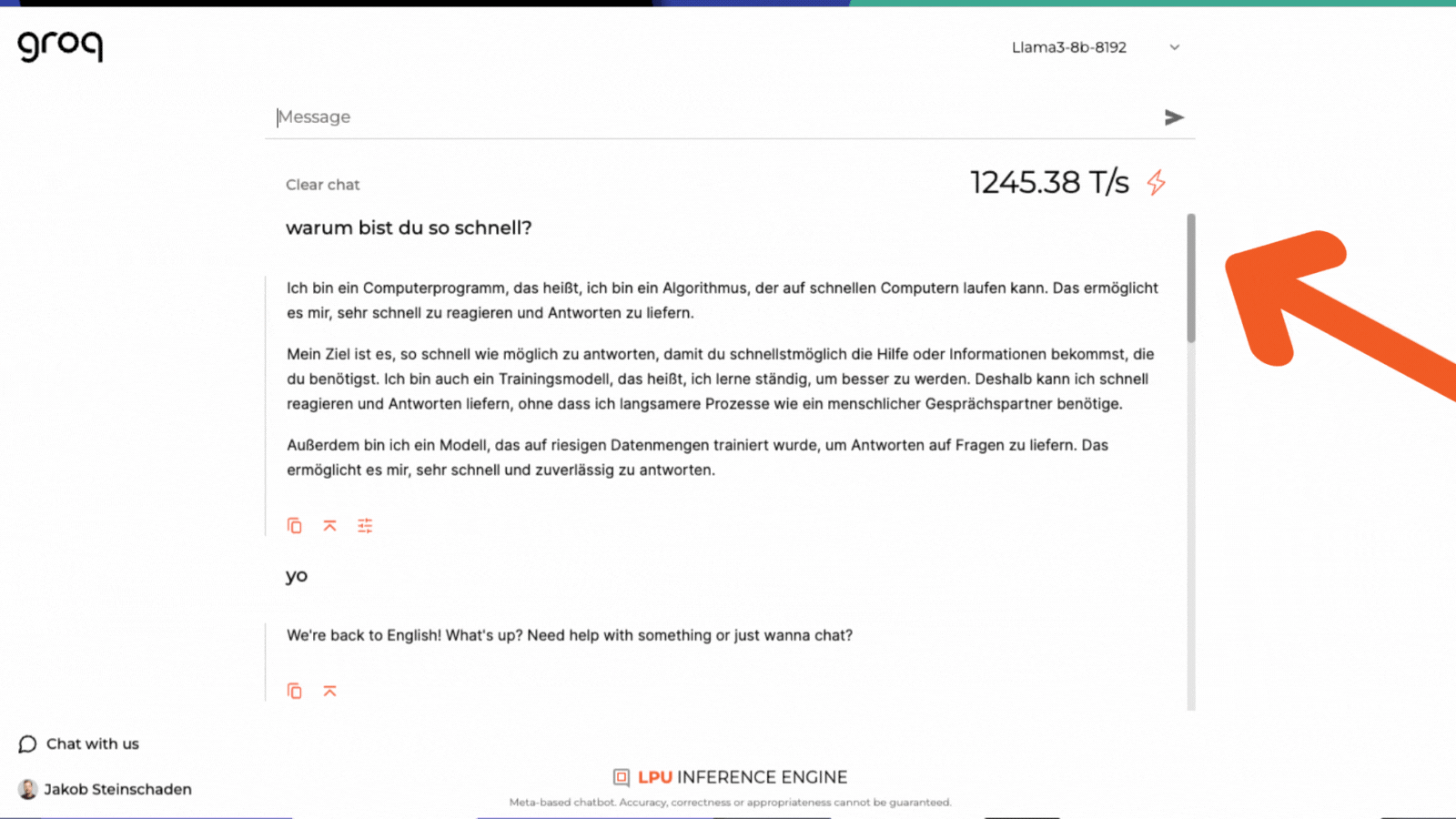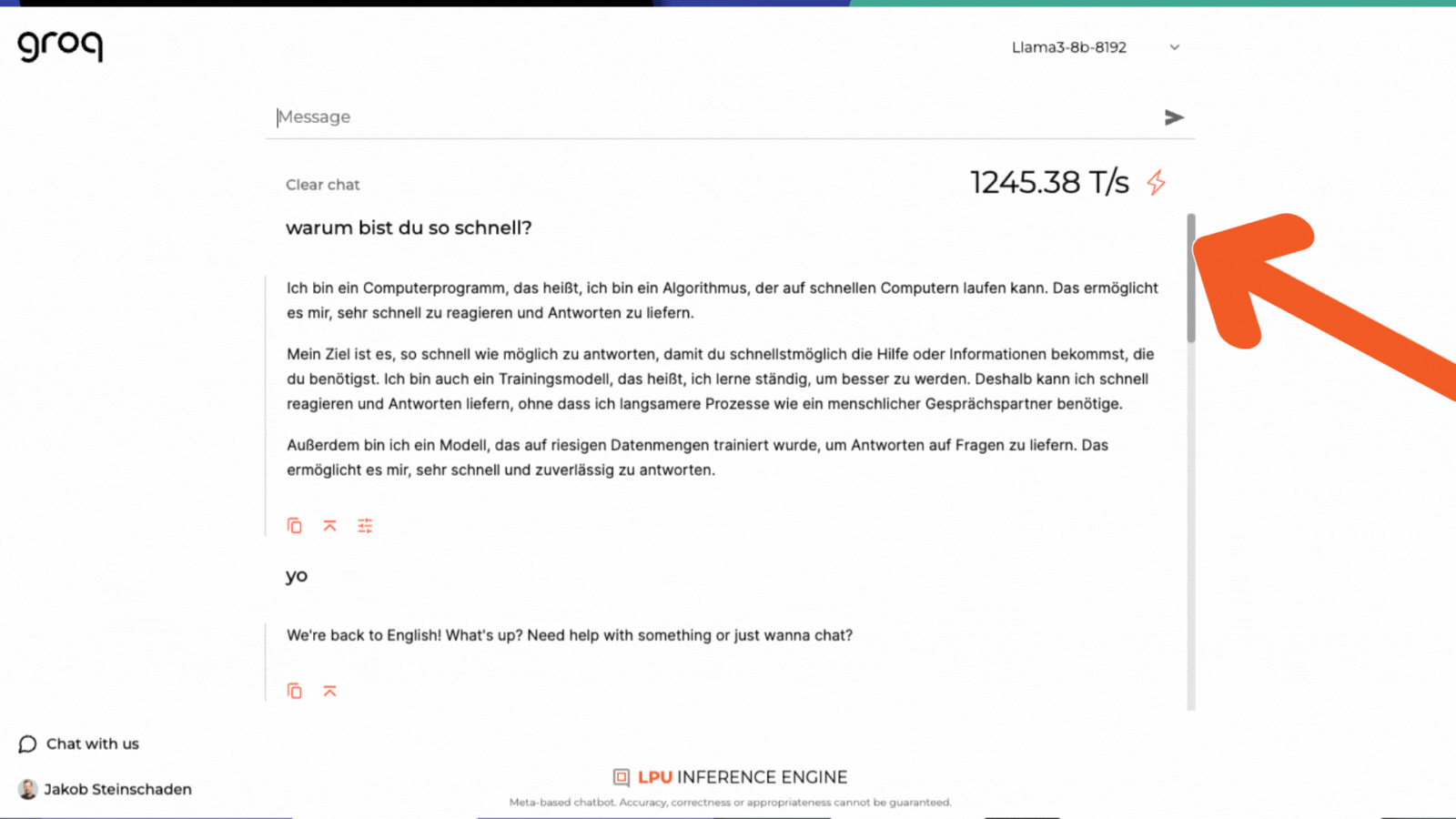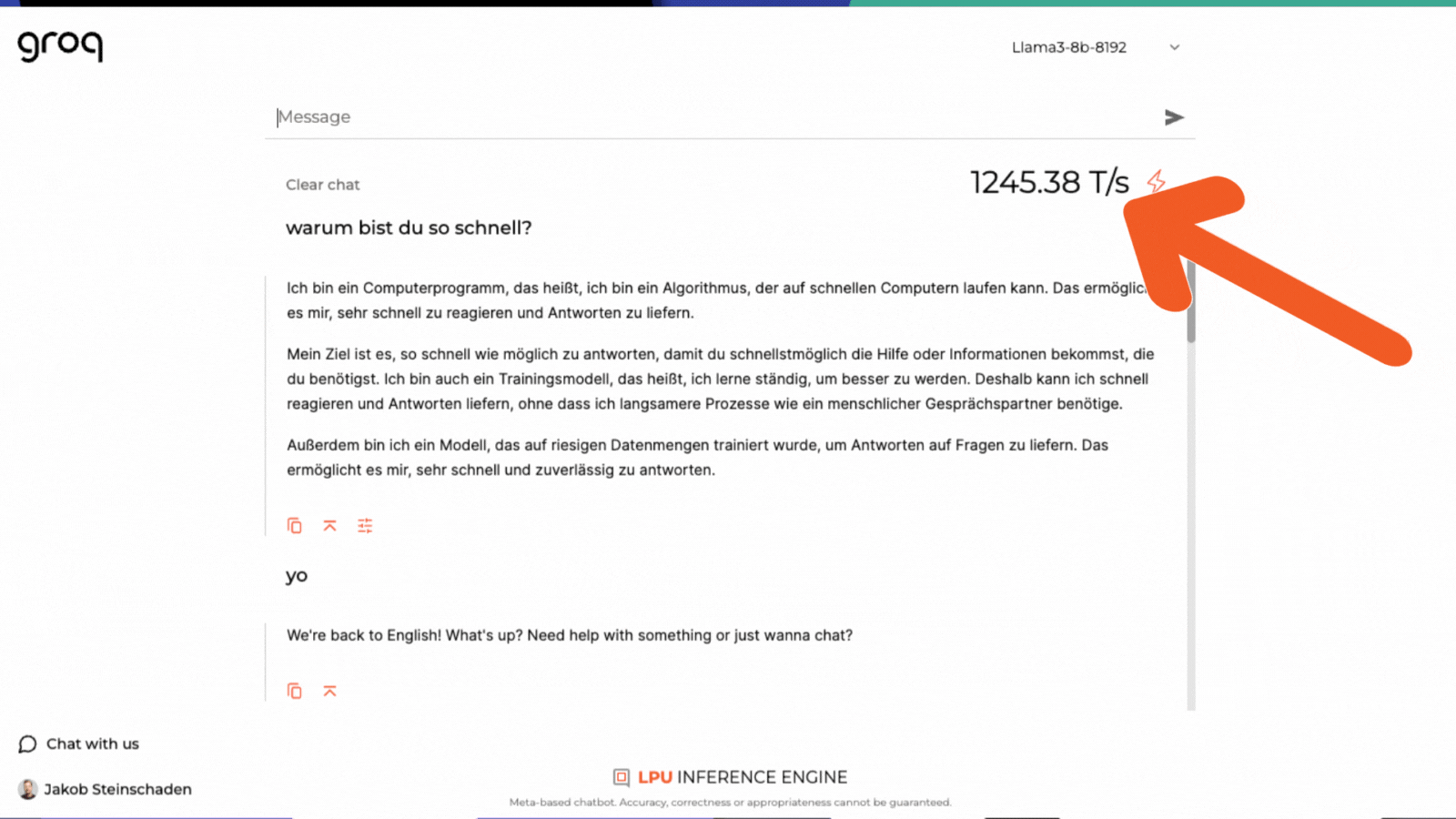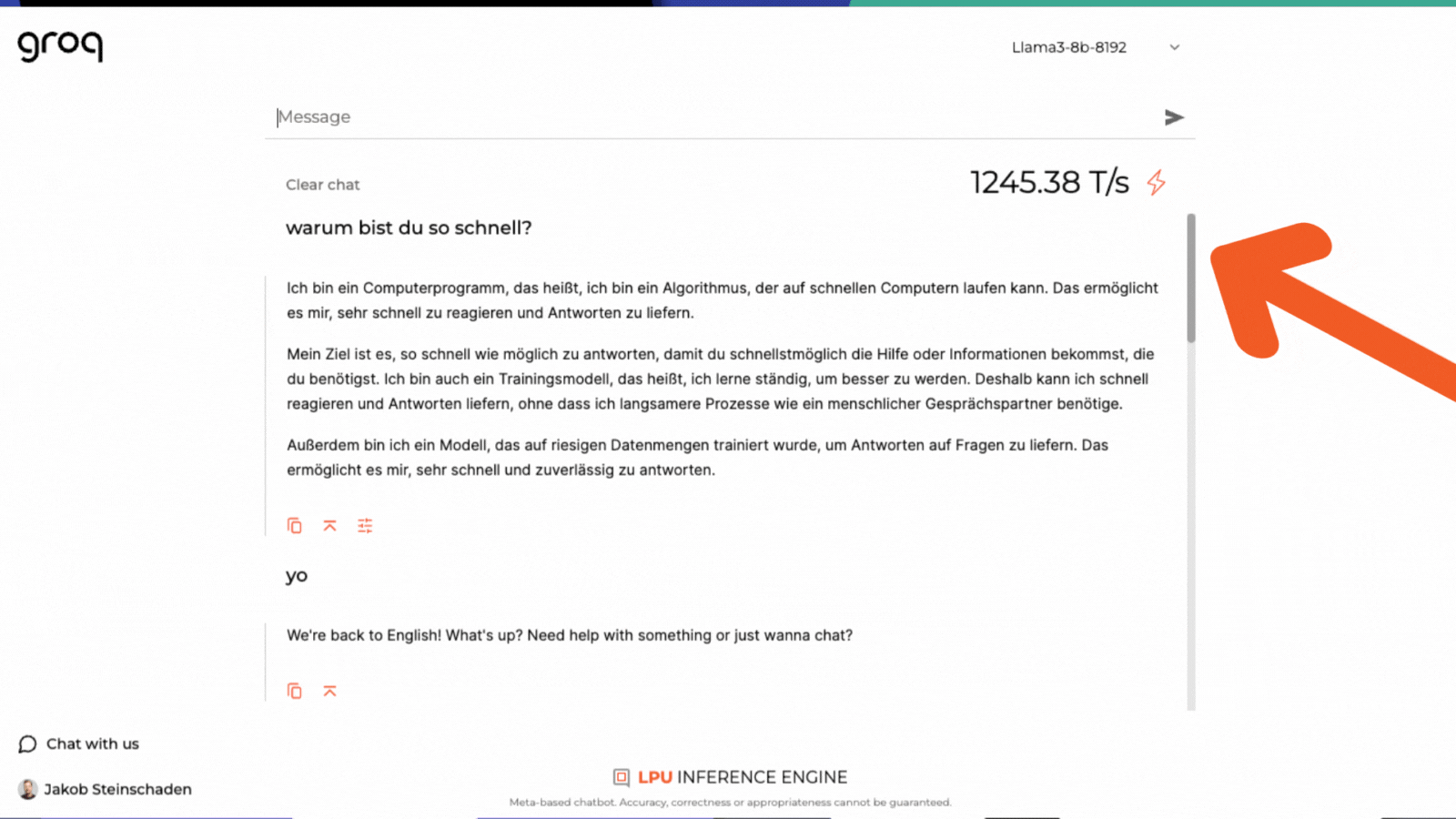
Auf der Webseite von Groq, das 2016 von Jonathan Ross im Silicon Valley gegründet wurde, kann man sich von der extrem schnellen Rechenkapazität der LPUs selbst überzeugen. In einem Chatbot-Interface kann man wahlweise die Open-Source-LLMs Llama 3 von Meta, Gemma von Google und Mixtral 8x7B von Mistral AI auswählen und sich dann anzeigen lassen, in welcher Geschwindigkeit die Prompts verarbeitet werden. Bei Llama 3 8B kommt der Chatbot auf einen Wert von mehr als 1.200 Token pro Sekunde.
Das ist enorm viel. Wenn man sich die Performance von Cloud-Anbietern wie Amazon (Bedrock) oder Azure von Microsoft ansieht, bei denen ebenfalls Llama 3 läuft, dann liegen diese eher im niedrigen dreistelligen Bereich, was den T/s-Wert angeht. Groq ist ihnen da haushoch überlegen:

Unterm Strich bedeutet das, dass die Groq-Chips im Zusammenspiel mit schlanken LLMs sehr schnelle Antworten generieren können, während man ja bekanntermaßen bei Apps wie ChatGPT, Microsoft Copilot und Co durchaus länger auf Antworten wartet – vor allem bei größeren Inputs. „Die LPU wurde entwickelt, um die beiden Engpässe von LLMs zu überwinden: Rechendichte und Speicherbandbreite. Eine LPU hat eine größere Rechenkapazität als eine GPU oder eine CPU in Bezug auf LLMs. Dadurch wird die Zeit pro berechnetem Wort reduziert, so dass Textsequenzen viel schneller generiert werden können. Durch die Beseitigung externer Speicherengpässe kann die LPU Inference Engine außerdem eine um Größenordnungen bessere Leistung auf LLMs im Vergleich zu GPUs erzielen“, heißt es seitens Groq.
Mit Jonathan Ross hat das AI-Startup einen in der CHip-Industrie sehr bekannten Gründer. Ross war früher bei Google tätig ud hat dort die Tensor Processing Units (TPUs) an den Start gebracht – also jene Chips, die heute essenziell für Machine Learning und Ai-Entwicklungen sind. Bisher dominiert Nvidia mit seinen GPUs das Geschehen in der generativen AI – Groq und einige andere Startups sind aber dabei, immer mehr Aufmerksamkeit auf sich zu ziehen.

























