With GPT-5.5, OpenAI is Making a Comeback to The Top of The AI Charts



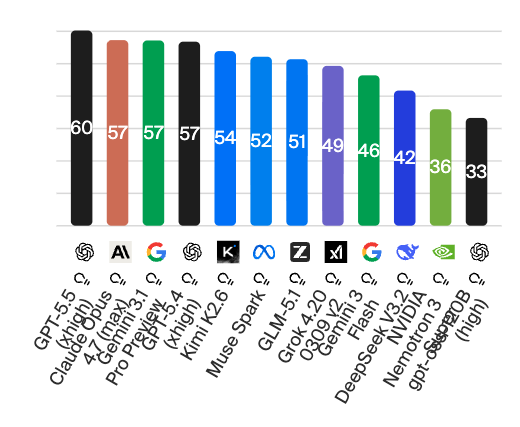
There has already been so much buzz in the AI industry beforehand that expectations for “Spud” (code name so far) are quite high. And one thing can be said: “Spud” aka GPT-5.5 from OpenAI does not disappoint. Quite the opposite — it surprises considerably. Because the new AI model actually manages to do what GPT-5 achieved (if only briefly): namely, positioning itself ahead of the AI models from competitors Anthropic and Google.
The model is aimed at users who want to delegate complex, multi-step tasks to an AI, and according to the manufacturer it is intended to make particular advances over its predecessor GPT-5.4 in the areas of programming, knowledge work, and scientific research. Here is the current ranking from Artificial Analysis, which clearly shows that GPT-5.5 can assert itself well ahead of Claude Opus 4.7 from Anthropic and Gemini 3.1 from Google:
The release includes two variants: the standard model GPT-5.5 and GPT-5.5 Pro for particularly demanding tasks. Both are being rolled out immediately in ChatGPT and Codex for Plus, Pro, Business, and Enterprise customers, with API availability set to follow shortly.
Performance Profile and Strengths
According to OpenAI, GPT-5.5 is designed primarily for agentic work. The model is intended to independently plan complex, multi-step tasks, use tools, review intermediate results, and see things through to completion — without users having to control every step individually. OpenAI reports particular advances in four areas: agentic coding, computer use, knowledge work, and early scientific research.
In the coding domain, GPT-5.5 achieves a peak score of 82.7 percent on Terminal-Bench 2.0 and solves significantly more problems than its predecessor GPT-5.4 on the internal Expert-SWE benchmark, which represents tasks with approximately 20 hours of human processing time. Noteworthy is the token efficiency: according to OpenAI, GPT-5.5 requires fewer tokens than GPT-5.4 for comparable Codex tasks and, by its own account, delivers state-of-the-art performance on the Artificial Analysis Coding Index at half the price of competing frontier coding models.
For knowledge work, OpenAI cites internal examples from within the company itself: the finance team used Codex to analyze 24,771 K-1 tax forms totaling 71,637 pages, accelerating the process by two weeks compared to the previous year. A go-to-market employee saves 5 to 10 hours per week through automated weekly reports.
In scientific research, OpenAI highlights advances on benchmarks such as GeneBench and BixBench. An internal variant of GPT-5.5 with a customized harness also found a new proof relating to Ramsey numbers in combinatorics, which was subsequently verified in Lean.
Efficiency and Infrastructure
GPT-5.5 was developed and deployed jointly with NVIDIA GB200 and GB300-NVL72 systems. Despite its higher capabilities, latency per token is said to remain comparable to GPT-5.4. OpenAI states that the model itself helped optimize the company’s own infrastructure — for example, in developing load-balancing heuristics that increased token generation speed by more than 20 percent.
Drawbacks and Open Questions
Despite the advances, there are also limitations, some of which OpenAI acknowledges itself:
Higher price: At $5 per million input tokens and $30 per million output tokens, GPT-5.5 is priced above GPT-5.4. GPT-5.5 Pro is considerably more expensive at $30 per million input tokens and $180 per million output tokens.
Stricter classifiers: OpenAI classifies GPT-5.5 as “High” risk in both biology/chemistry and cybersecurity under the Preparedness Framework. As a result, stricter filters have been implemented which, according to OpenAI itself, “may initially be perceived as annoying.” Legitimate security researchers must verify themselves through a “Trusted Access for Cyber” program in order to work with fewer restrictions.
API availability delayed: While ChatGPT and Codex users have immediate access, the API version will not be available until later. OpenAI attributes this to outstanding security requirements for operation at scale.
Weaknesses with long contexts in mid-range segments: On certain OpenAI-MRCR-v2 tests (approximately 16K–32K and 32K–64K), GPT-5.5 falls slightly below GPT-5.4, while it performs significantly better at very long contexts (up to 1 million tokens).
Benchmark limitations: For SWE-Bench Pro, OpenAI itself points out that labs have found indications of memorization effects — meaning the informative value of this benchmark is limited. The note that Tau2-bench Telecom was evaluated by other labs with prompt adjustments also makes direct comparison more difficult.
Competition remains ahead in individual disciplines: On several benchmarks, GPT-5.5 does not rank at the top (see table).
Comparison with Claude Opus 4.7 and Gemini 3.1 Pro
The following table shows the benchmark values published by OpenAI. They come exclusively from the OpenAI announcement and should be interpreted accordingly — independent verification of the competitor values by Anthropic or Google is not available here.
| Benchmark | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Terminal-Bench 2.0 (Coding) | 82.7% | 69.4% | 68.5% |
| SWE-Bench Pro (Coding) | 58.6% | 64.3% | 54.2% |
| GDPval (Knowledge Work) | 84.9% | 80.3% | 67.3% |
| OSWorld-Verified (Computer Use) | 78.7% | 78.0% | – |
| BrowseComp (Tool Use) | 84.4% | 79.3% | 85.9% |
| MCP Atlas (Tool Use) | 75.3% | 79.1% | 78.2% |
| FrontierMath Tier 1–3 | 51.7% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 22.9% | 16.7% |
| GPQA Diamond | 93.6% | 94.2% | 94.3% |
| Humanity’s Last Exam (with Tools) | 52.2% | 54.7% | 51.4% |
| CyberGym | 81.8% | 73.1% | – |
| ARC-AGI-1 | 95.0% | 93.5% | 98.0% |
| ARC-AGI-2 | 85.0% | 75.8% | 77.1% |
GPT-5.5 clearly positions itself as an agentic work model with a focus on coding, knowledge work, and scientific research. In the benchmarks selected by OpenAI, it leads in many areas over Claude Opus 4.7 and Gemini 3.1 Pro — most notably in mathematical tasks (FrontierMath) and Terminal-Bench. Conversely, Claude Opus 4.7 retains an advantage on SWE-Bench Pro, MCP Atlas, and Humanity’s Last Exam with Tools, while Gemini 3.1 Pro leads on ARC-AGI-1 and BrowseComp.
For all those building their workflows on the basis of large language models, the choice therefore remains a matter of weighing specific strengths, costs, and security restrictions. Whether GPT-5.5 delivers the promised productivity leaps at scale will only become clear in the coming weeks, once the API version is available and independent tests are on hand.


























