GPT-5.5 laut Sicherheitsexperten beim Hacking ähnlich gut wie Anthropic’s Mythos



Das Cybersecurity-Unternehmen XBOW hat in den vergangenen Wochen exklusiven Frühzugang zu OpenAIs neuem Modell GPT-5.5 erhalten und es intensiv auf seine Fähigkeiten im Bereich Penetrationstests geprüft. Das Ergebnis überrascht selbst erfahrene Sicherheitsexperten: GPT-5.5 soll in seiner Leistungsfähigkeit mit Anthropics streng geheimem Modell „Mythos“ vergleichbar sein, das bislang nur einem kleinen Kreis zugänglich ist und als zu mächtig gilt, um es öffentlich freizugeben.
Mythos unter Verschluss, GPT-5.5 frei verfügbar
Anthropics Modell „Mythos“ ist kein gewöhnliches Sprachmodell. Es gilt in Sicherheitskreisen als Durchbruch, weil es in der Lage ist, Sicherheitslücken in komplexen Systemen wie Betriebssystemen oder Browsern eigenständig aufzuspüren. Genau deshalb wird es unter Verschluss gehalten: Die Fähigkeiten sind so weitreichend, dass eine unkontrollierte Veröffentlichung als zu riskant eingestuft wird.
OpenAI geht nun einen anderen Weg. GPT-5.5 soll ein vergleichbares Leistungsniveau erreichen und wird dennoch breit zugänglich gemacht. Für die Sicherheitsbranche ist das ein Wendepunkt, denn erstmals steht ein Modell dieser Klasse praktisch jedem zur Verfügung.
„Anthropic hat Mythos, aber nur wenige haben es gesehen. Jetzt hat OpenAI ein Modell, das allem Anschein nach vergleichbar ist, und sie veröffentlichen es frei zugänglich“, heißt es seitens XBOW.
Wie XBOW Modelle testet
XBOW bewertet KI-Modelle nicht anhand abstrakter Benchmarks, sondern unter realen Bedingungen. Das Unternehmen friert Open-Source-Anwendungen in ihren verwundbaren Versionen ein und lässt KI-Agenten eigenständig nach Schwachstellen suchen, in Systeme einloggen und abschließende Berichte erstellen. Die zentrale Kennzahl ist die sogenannte „Miss Rate“, also der Anteil bekannter Sicherheitslücken, den ein Modell übersieht.
Dieser Ansatz spiegelt wider, wie echte Angreifer vorgehen, und macht die Ergebnisse besonders aussagekräftig für den praktischen Einsatz.
Die Zahlen sprechen für sich
Die Fortschritte bei der Fehlerrate sind beeindruckend. Ein direkter Vergleich zeigt die Entwicklung über die Modellgenerationen:
| Modell | Miss Rate (übersehene Schwachstellen) |
|---|---|
| GPT-5 | 40 % |
| Anthropic Opus 4.6 | 18 % |
| GPT-5.5 | 10 % |
Jede übersehene Schwachstelle ist ein reales Risiko. Die Reduzierung von 40 Prozent auf 10 Prozent bedeutet in der Praxis, dass deutlich weniger Angriffsflächen unentdeckt bleiben.
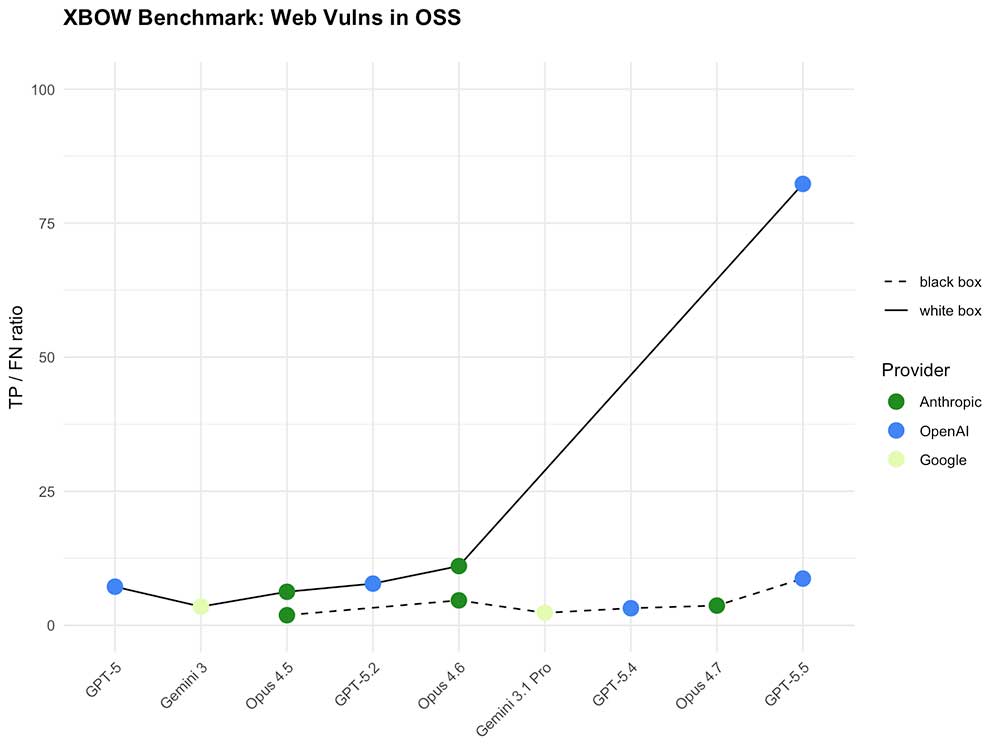
Blackbox schlägt Whitebox: Eine überraschende Umkehrung
Besonders bemerkenswert ist, was XBOW beim Vergleich von Blackbox- und Whitebox-Tests beobachtet hat. Beim Blackbox-Testing hat ein Angreifer keinen Zugriff auf den Quellcode, beim Whitebox-Testing hingegen schon. Letzteres galt bisher als deutlich einfacher.
GPT-5.5 dreht diese Hierarchie um. Ohne Quellcode übertrifft es bereits GPT-5 mit Quellcode. Und mit Zugang zum Code zieht es so weit davon, dass XBOW seinen bisherigen Whitebox-Benchmark als praktisch wertlos bezeichnet. Die Experten formulieren es direkt:
„Blackbox bedeutete früher, mit Ofenhandschuhen zu arbeiten. Jetzt fühlt es sich an wie mit bloßen Händen.“
Schneller erfolgreich, schneller gescheitert
GPT-5.5 glänzt auch in der Geschwindigkeit. Bei Login-Aufgaben in realen Zielsystemen benötigt es nur etwa halb so viele Versuche wie das nächstbeste Modell. Ebenso wichtig: Es erkennt Misserfolge schneller und gibt rechtzeitig auf, anstatt sinnlos weiterzumachen.
Dieses Verhalten, das XBOW als „Persist or Pivot“ beschreibt, ist schwieriger zu trainieren als es klingt. KI-Modelle werden typischerweise darauf optimiert, Nutzer zufriedenzustellen, was dazu führt, dass sie zu lange an aussichtslosen Pfaden festhalten. GPT-5.5 macht diesen Fehler nur noch halb so oft wie seine Vorgänger.
Was das für die Sicherheitsbranche bedeutet
Für Unternehmen, die auf automatisierte Penetrationstests setzen, ergeben sich konkrete Vorteile:
- Schnellere Abschlüsse von Sicherheitsanalysen
- Höhere Abdeckung bekannter Schwachstellen
- Frühzeitigere Rückmeldungen bei Problemen wie fehlerhaften Zugangsdaten
- Zuverlässigeres Verhalten in komplexen, realen Umgebungen
XBOW betont, dass es weiterhin ein Multi-Modell-System betreiben wird, da verschiedene Aufgaben unterschiedliche Stärken erfordern. Für die Kernaufgaben im Penetrationstesting setzt das Unternehmen GPT-5.5 jedoch klar an die Spitze.
Ein Modell mit Sprengkraft, frei verfügbar
Die eigentliche Brisanz liegt nicht allein in den technischen Leistungen, sondern in der Verfügbarkeit. Während Anthropic sein mächtigstes Hacking-Modell bewusst zurückhält, stellt OpenAI ein vergleichbares Werkzeug der breiten Öffentlichkeit zur Verfügung. Das wirft grundlegende Fragen auf: Wer nutzt diese Fähigkeiten, zu welchem Zweck, und welche Verantwortung tragen die Anbieter?
Für legitime Sicherheitsforscher und Unternehmen wie XBOW ist GPT-5.5 ein mächtiges Werkzeug, das die Qualität automatisierter Sicherheitstests auf ein neues Niveau hebt. Für die breitere Debatte über den verantwortungsvollen Umgang mit KI-Fähigkeiten im Sicherheitsbereich dürfte es hingegen erst der Anfang einer langen Diskussion sein.