OpenAI kehrt mit GPT-5.5 an die Spitze der KI-Modelle zurück



Im Vorfeld hat es schon derart in der KI-Branche rumort, dass die Erwartungen an „Spud“ (Codename bisher) doch ziemlich hoch sind. Und eines kann man sagen: „Spud“ aka GPT-5.5 von OpenAI enttäuscht nicht. Sondern überrascht ordentlich. Denn das neue KI-Modell schafft es tatsächlich, was zu GPT-5 (nur ganz kurz) geschafft hat. Nämlich sich vor die KI-Modelle der Konkurrenten von Anthropic und Google zu setzen.
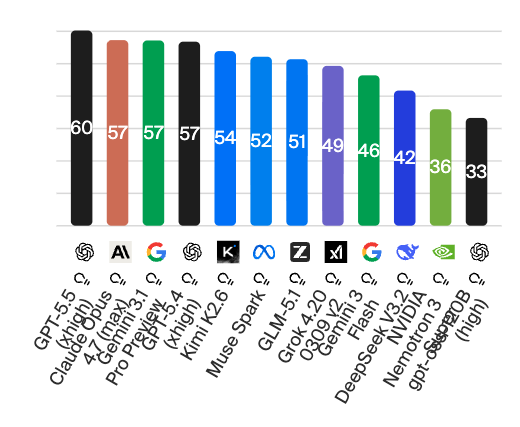
Das Modell richtet sich an Nutzer, die komplexe, mehrstufige Aufgaben an eine KI delegieren möchten, und soll laut Hersteller besonders in den Bereichen Programmierung, Wissensarbeit und wissenschaftliche Forschung Fortschritte gegenüber dem Vorgänger GPT-5.4 erzielen. Hier das aktuelle Ranking von Artificial Analysis, das deutlich zeigt, dass sich GPT-5.5 doch deutlich vor Claude Opus 4.7 von Anthropic und Gemini 3.1 von Google behaupten kann:
Der Release umfasst zwei Varianten: das Standardmodell GPT-5.5 sowie GPT-5.5 Pro für besonders anspruchsvolle Aufgaben. Beide werden ab sofort in ChatGPT und Codex für Plus-, Pro-, Business- und Enterprise-Kunden ausgerollt, die API-Verfügbarkeit soll kurzfristig folgen.
Leistungsprofil und Stärken
GPT-5.5 ist laut OpenAI vor allem auf agentisches Arbeiten ausgelegt. Das Modell soll komplexe, mehrstufige Aufgaben eigenständig planen, Werkzeuge nutzen, Zwischenergebnisse prüfen und bis zum Abschluss durchhalten – ohne dass Nutzer jeden Schritt einzeln steuern müssen. Besondere Fortschritte verzeichnet OpenAI in vier Bereichen: agentisches Programmieren, Computer Use, Wissensarbeit und frühe wissenschaftliche Forschung.
Im Coding-Bereich erreicht GPT-5.5 auf Terminal-Bench 2.0 einen Spitzenwert von 82,7 Prozent und löst auf dem internen Expert-SWE-Benchmark, der Aufgaben mit rund 20 Stunden menschlicher Bearbeitungsdauer abbildet, deutlich mehr Probleme als der Vorgänger GPT-5.4. Bemerkenswert ist dabei die Token-Effizienz: Laut OpenAI benötigt GPT-5.5 für vergleichbare Codex-Aufgaben weniger Tokens als GPT-5.4 und liefert auf dem Artificial Analysis Coding Index nach eigenen Angaben State-of-the-Art-Leistung zum halben Preis konkurrierender Frontier-Coding-Modelle.
Für Wissensarbeit nennt OpenAI interne Beispiele aus dem eigenen Unternehmen: Das Finanzteam habe mit Codex 24.771 K-1-Steuerformulare mit insgesamt 71.637 Seiten analysiert und den Prozess gegenüber dem Vorjahr um zwei Wochen beschleunigt. Ein Go-to-Market-Mitarbeiter spare durch automatisierte Wochenberichte 5 bis 10 Stunden pro Woche.
In der wissenschaftlichen Forschung hebt OpenAI Fortschritte auf Benchmarks wie GeneBench und BixBench hervor. Eine interne Variante von GPT-5.5 mit angepasstem Harness habe zudem einen neuen Beweis zu Ramsey-Zahlen aus der Kombinatorik gefunden, der später in Lean verifiziert wurde.
Effizienz und Infrastruktur
GPT-5.5 wurde gemeinsam mit NVIDIA GB200- und GB300-NVL72-Systemen entwickelt und ausgeliefert. Trotz höherer Fähigkeiten soll die Latenz pro Token mit GPT-5.4 vergleichbar bleiben. OpenAI gibt an, dass das Modell selbst bei der Optimierung der eigenen Infrastruktur geholfen habe – etwa bei der Entwicklung von Load-Balancing-Heuristiken, die die Token-Generierungsgeschwindigkeit um über 20 Prozent gesteigert hätten.
Nachteile und offene Fragen
Trotz der Fortschritte gibt es auch Einschränkungen, die OpenAI teils selbst einräumt:
Höherer Preis: Mit 5 US-Dollar pro Million Input-Tokens und 30 US-Dollar pro Million Output-Tokens liegt GPT-5.5 über dem Preis von GPT-5.4. GPT-5.5 Pro ist mit 30 Dollar pro Million Input- und 180 Dollar pro Million Output-Tokens deutlich teurer.
Strengere Klassifikatoren: OpenAI stuft GPT-5.5 sowohl in Biologie/Chemie als auch in Cybersecurity als „High“-Risiko im Rahmen des Preparedness Framework ein. In der Folge wurden strengere Filter implementiert, die laut OpenAI selbst „zunächst als lästig empfunden werden könnten“. Legitime Sicherheitsforscher müssen sich über ein „Trusted Access for Cyber“-Programm verifizieren lassen, um mit weniger Einschränkungen arbeiten zu können.
API-Verfügbarkeit verzögert: Während ChatGPT- und Codex-Nutzer sofortigen Zugriff haben, ist die API-Version erst später verfügbar. OpenAI begründet dies mit noch offenen Sicherheitsanforderungen für den Betrieb in großem Maßstab.
Schwächen bei langen Kontexten in mittleren Bereichen: Auf einzelnen OpenAI-MRCR-v2-Tests (etwa 16K-32K und 32K-64K) liegt GPT-5.5 leicht unter GPT-5.4, während es bei sehr langen Kontexten (bis 1 Million Tokens) deutlich vorne liegt.
Benchmark-Einschränkungen: Bei SWE-Bench Pro weist OpenAI selbst darauf hin, dass Labore Hinweise auf Memorisierungseffekte gefunden haben – die Aussagekraft dieses Benchmarks ist also eingeschränkt. Auch der Hinweis, dass Tau2-bench Telecom bei anderen Laboren mit Prompt-Anpassungen evaluiert wurde, erschwert den direkten Vergleich.
Konkurrenz bleibt in einzelnen Disziplinen vorne: Bei mehreren Benchmarks liegt GPT-5.5 nicht an der Spitze (siehe Tabelle).
Vergleich mit Claude Opus 4.7 und Gemini 3.1 Pro
Die folgende Tabelle zeigt die von OpenAI veröffentlichten Benchmark-Werte. Sie stammen ausschließlich aus der OpenAI-Ankündigung und sollten entsprechend eingeordnet werden – unabhängige Verifizierungen der Konkurrenz-Werte durch Anthropic oder Google liegen hier nicht vor.
| Benchmark | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|
| Terminal-Bench 2.0 (Coding) | 82,7 % | 69,4 % | 68,5 % |
| SWE-Bench Pro (Coding) | 58,6 % | 64,3 % | 54,2 % |
| GDPval (Wissensarbeit) | 84,9 % | 80,3 % | 67,3 % |
| OSWorld-Verified (Computer Use) | 78,7 % | 78,0 % | – |
| BrowseComp (Tool Use) | 84,4 % | 79,3 % | 85,9 % |
| MCP Atlas (Tool Use) | 75,3 % | 79,1 % | 78,2 % |
| FrontierMath Tier 1–3 | 51,7 % | 43,8 % | 36,9 % |
| FrontierMath Tier 4 | 35,4 % | 22,9 % | 16,7 % |
| GPQA Diamond | 93,6 % | 94,2 % | 94,3 % |
| Humanity’s Last Exam (mit Tools) | 52,2 % | 54,7 % | 51,4 % |
| CyberGym | 81,8 % | 73,1 % | – |
| ARC-AGI-1 | 95,0 % | 93,5 % | 98,0 % |
| ARC-AGI-2 | 85,0 % | 75,8 % | 77,1 % |
GPT-5.5 positioniert sich klar als agentisches Arbeitsmodell mit Schwerpunkt auf Coding, Wissensarbeit und wissenschaftlicher Forschung. In den von OpenAI ausgewählten Benchmarks liegt es in vielen Bereichen vor Claude Opus 4.7 und Gemini 3.1 Pro – besonders deutlich bei mathematischen Aufgaben (FrontierMath) und Terminal-Bench. Umgekehrt behält Claude Opus 4.7 einen Vorsprung bei SWE-Bench Pro, MCP Atlas und Humanity’s Last Exam mit Tools, während Gemini 3.1 Pro bei ARC-AGI-1 und BrowseComp führt.
Für all jene, die ihre Workflows auf Basis großer Sprachmodelle aufbauen, bleibt die Wahl also weiterhin eine Abwägung zwischen spezifischen Stärken, Kosten und Sicherheitsrestriktionen. Ob GPT-5.5 die versprochenen Produktivitätssprünge in der Breite liefert, wird sich erst in den kommenden Wochen zeigen, wenn die API-Version verfügbar ist und unabhängige Tests vorliegen.