GPT-5.5 im Vergleich: Nicht überall top, bei deutlichen Preissteigerungen



Für OpenAI war die Veröffentlichung von GPT-5.5 vor einer Woche ein großes Ding. Zum einen ist es das erste KI-Modell seit längerem, dass ein komplettes Pre-Training bekommen hat – und es soll das Fundament für alles weitere legen, das mit KI-Agenten zu tun hat. In den von OpenAI herausgegebenen Benchmarks brilliert das neue LLM natürlich auch im Vergleich zu den beiden Hauptkonkurrenten Claude Opus 4.7 von Anthropic und Gemini 3.1 Pro von Google.
Wie aber sieht es mit unabhängigen Tests aus? Hier zeigt sich nun ein gemischtes Bild. Bei Arena.ai, wo User im Blindtest die Outputs von KI-Modellen bewerten, schafft es GPT-5.5 aktuell nicht an die LLMs von Anthropic (sowohl Claude Opus 4.7 als auch 4.6), Gemini 3.1 Pro von Google sowie interessanterweise Muse Spark von Meta vorbei.
Hier das aktuelle Ranking:
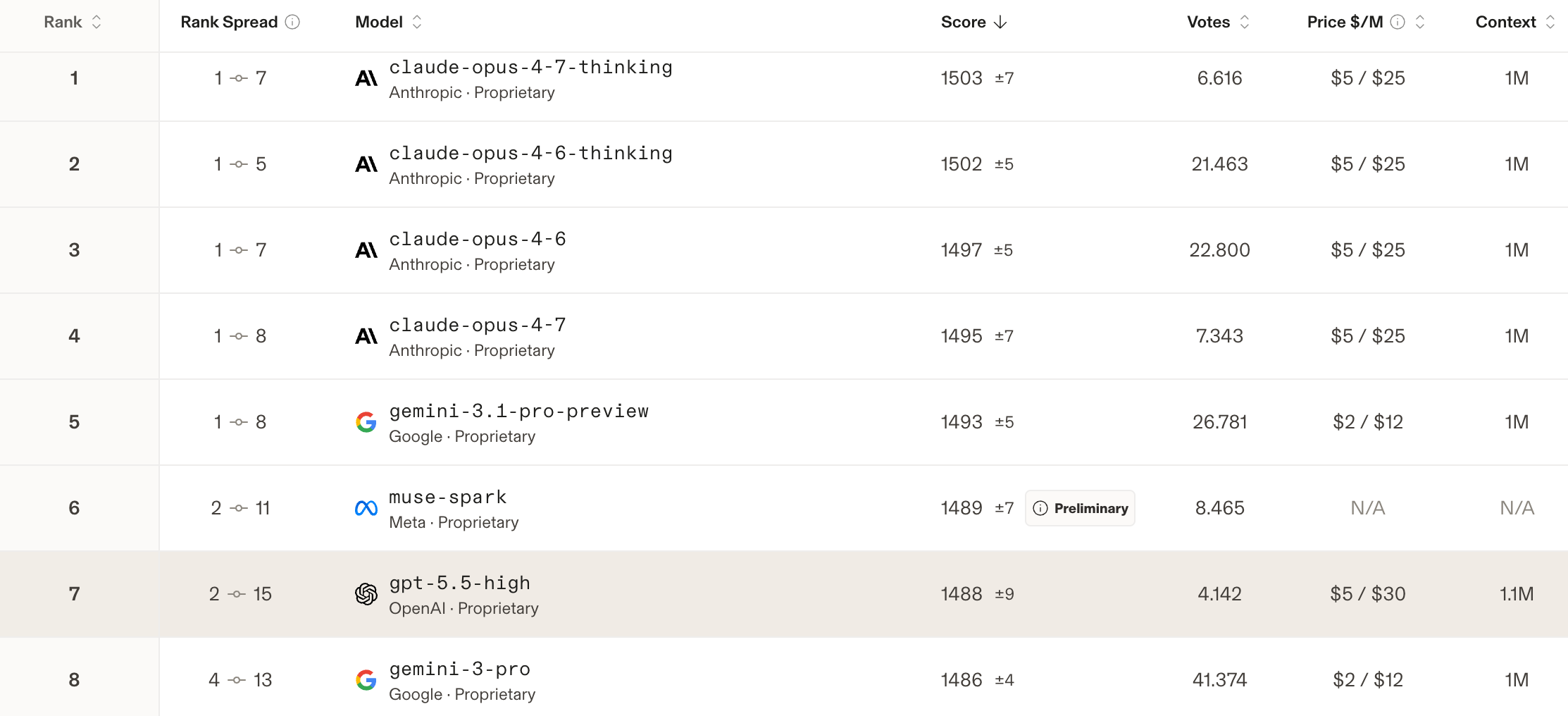
Im Gegensatz zum Artificial Analysis Intelligence Index, der KI-Modelle anhand standardisierter akademischer Tests bewertet, verfolgt LMArena (arena.ai) einen grundlegend anderen Ansatz: Hier entscheiden echte Nutzerpräferenzen über das Ranking. Auf der Plattform geben Nutzerinnen und Nutzer einen beliebigen Prompt ein und erhalten parallel Antworten von zwei anonymen KI-Modellen. Sie wählen die aus ihrer Sicht bessere Antwort, ohne zu wissen, welches Modell dahintersteht – erst nach der Abstimmung werden die Namen aufgedeckt. Aus Millionen solcher Blind-Duelle berechnet LMArena mithilfe des Bradley-Terry-Modells – einer Weiterentwicklung des aus dem Schach bekannten ELO-Systems – eine fortlaufend aktualisierte Rangliste.
Top-Ergebnisse bei Artificial Analysis
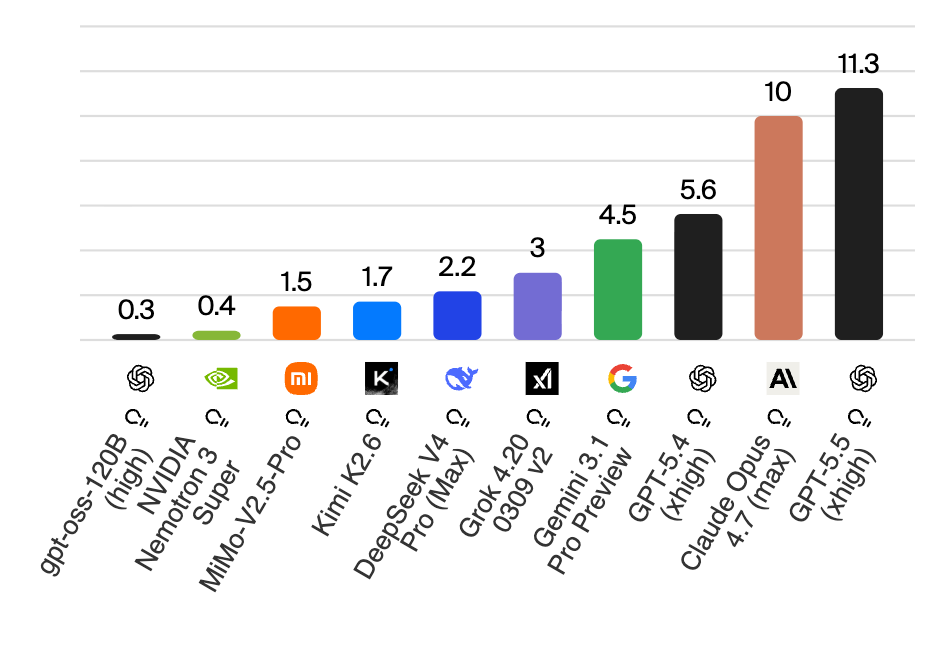
Hingegen bei Artificial Analysis liegt GPT-5.5 (in der Version „xhigh“) aktuell auf Platz 1 vor Claude Opus 4.7 und Gemini 3.1 Pro. Der Unterschied in der Messung zu Arena.ai: Während dort User bewerten, werden bei Artificial Analysis zehn verschiedene Tests kombiniert, die jeweils unterschiedliche Fähigkeiten abprüfen – grob in vier Kategorien:
- Logisches Denken & Schlussfolgern (z. B. Humanity’s Last Exam, GPQA Diamond)
- Wissen (z. B. AA-Omniscience, AA-LCR)
- Mathematik & Wissenschaft (z. B. SciCode, CritPt)
- Programmieren & praktische Aufgaben (z. B. Terminal-Bench Hard, GDPval-AA, 𝜏²-Bench Telecom, IFBench)
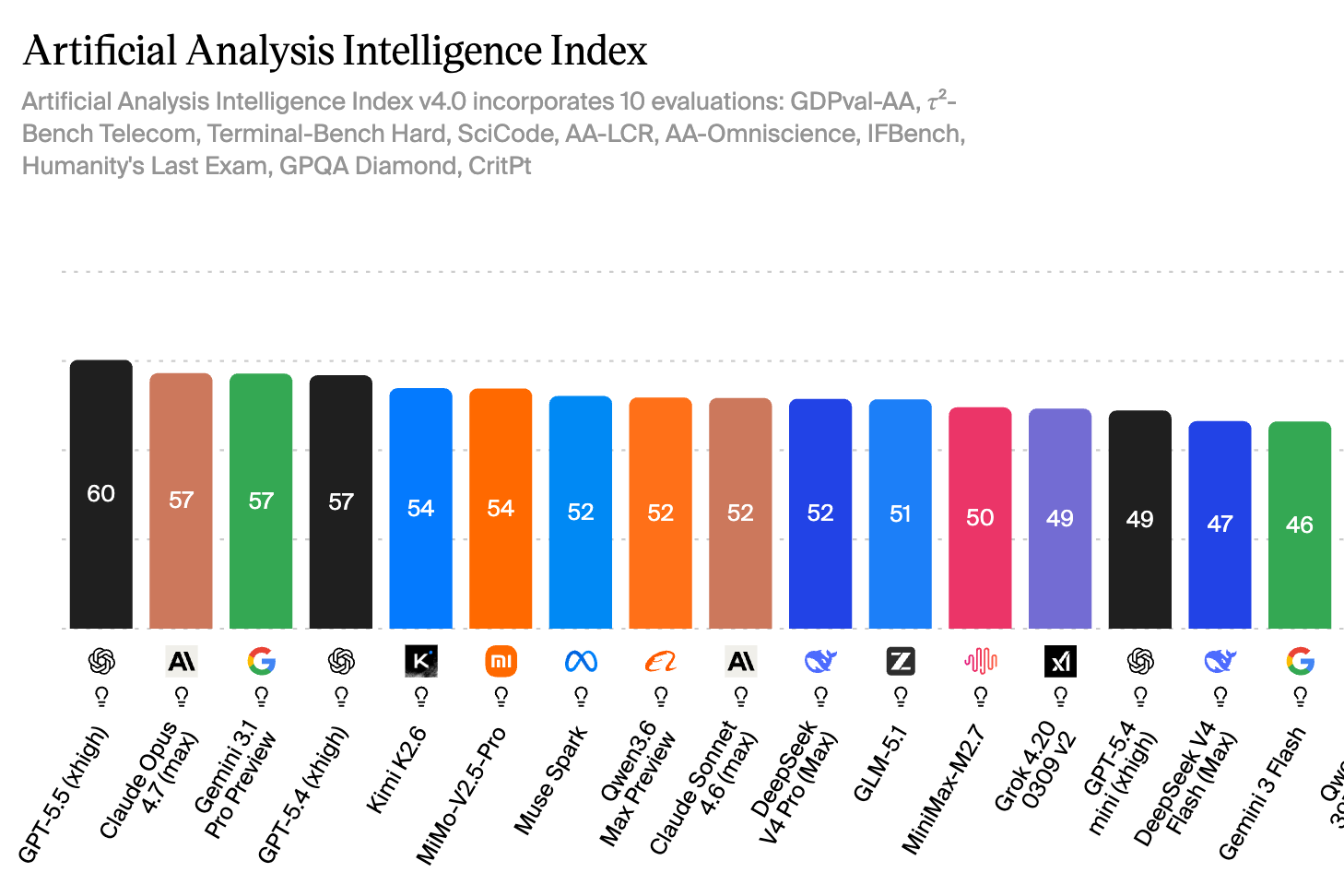
Teurer als die Konkurrenz
Was mit der gesteigerten Leistungsfähigkeit ebenfalls einhergeht, ist eine Teuerung. „GPT-5.5 (High) gehört zu den führenden Modellen in Bezug auf die Intelligenz, ist jedoch im Vergleich zu anderen Modellen in derselben Preisklasse besonders teuer“, heißt es seitens Artificial Analysis. Hier der Vergleich zu den hauseigenen Alternativen:
| Model | Input Price (per 1M tokens) | Output Price (per 1M tokens) |
| GPT-5.4 | $2.50 | $15.00 |
| GPT-5.5 | $5.00 | $30.00 |
| GPT-5.5 Pro | $30.00 | $180.00 |
Im Vergleich zu den KI-Modellen der Konkurrenz ist OpenAI nun mit GPT-5.5 am teuersten: